Screen Capture Your Whole Website
One of my clients recently needed to copyright their website. After speaking with their lawyers, I learned they needed all the source code, images, a list of technologies we didn't create (gems, frameworks, etc) and a screen shot of every page on the site.
The first requirements were easily obtained. I downloaded the github repo for the source code and images. I took the Gemfile and bower.json file and created a list of technologies that we didn't create. But, the screen capture thing was a bit of a quandary. The site has over 500 pages and capturing a full page screen shot(scroll and all) is a tedious task.
Then I remembered reading about a gem called capybara-screenshot and started tinkering with a short little program to take a screen shot of all the pages on the site. This is what I came up with:
require 'pry'
require 'capybara'
require 'capybara/dsl'
require 'capybara-screenshot'
Capybara.default_driver = :selenium
Capybara.app_host = 'http://www.example.com'
Capybara.save_and_open_page_path = "screenshots"
class Screenshot
include Capybara::DSL
def initialize(urls)
@urls = urls
end
def crawl_and_snap
@urls.each do |url|
snap url
end
end
def snap(path)
visit path
Capybara::Screenshot::Saver.new(
Capybara,
Capybara.page,
false,
image_name(path)).save
end
def image_name(path)
path.gsub("/", "-")
end
end
It wasn't that difficult, but I hit several small snags along the way...
Getting Capybara to work outside of rails or rack
I love Capybara and use it in almost every rails app I work on. However,
I've never used it outside of rails. At first I just tried to setup a
regular _spec file and run it, but I guess because the file wasn't
located in features it wasn't expecting to use Capybara. So I found that
you can simply use the Capybara::DSL module and get all of the methods
we want (visit, find, etc).
Taking the screen shot
Capybara::Screenshot is a simple little tool to use. Normally you'd just
call screenshot_and_save_page which I did at first, but it gives you a
file name like Screenshot-2014-07-28.png. I wanted the filenames to be
equivalent to the web uri (ie /about should be saved as about.png).
I didn't see a way to pass a filename to the screenshot_and_save_page
method, so after digging in the source, I saw that that method just
calls Capybara::Screenshot::Saver.new and then calls save on that.
It took 4 arguments. The first two were related to the capybara visit.
The third was whether to also save an html file and the fourth the
filename. Notice there's also a config you can set for the default
directory to save the images.
Web Driver
I wanted to use something other than Selenium so Firefox wasn't running, but I tried webkit and PhantomJS and both worked, but had several issues like missing images and default width of the page (caused my responsive site to hit a breakpoint). And the resulting image with the Selenium driver was super crisp.
Urls to Capture
I didn't really have a problem getting all of the urls we needed to crawl. I use the great sitemap_generator gem to create an xml sitemap for the site, so it was easy to get an output of all the urls for the site.
A couple of other ideas if you don't have a list of all the urls:
1) Use a crawler like wombat or anemone to crawl your site, get a path and then use the Screenshot class to snap it.
2) If you're satisified that google has all of your pages indexed, then you could use the google-search gem to fetch all of the pages in their index, get the urls and pass them to Screenshot. Example:
search = Google::Search::Web.new do |search|
search.query = "site:www.example.com"
search.size = :large
end
urls = search.all.map(&:uri)
Screenshot.new(urls).crawl_and_snap
Example
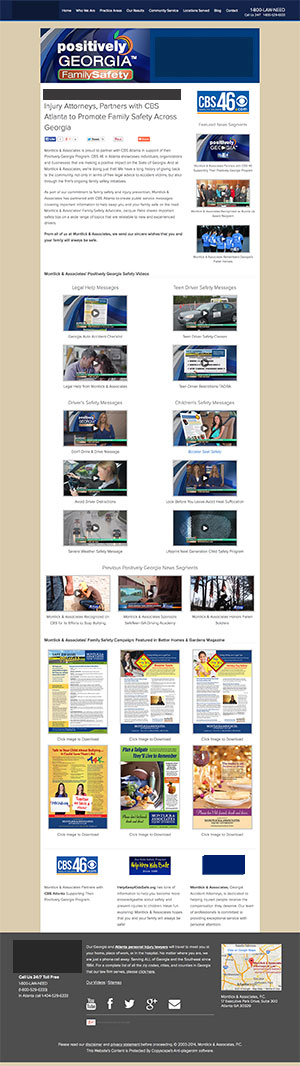
I blocked out my clients name and downsized it, but you can see how it does a nice job of capturing the whole page.
I was thinking about creating a small gem out of it. What do you think, would it be useful?